

Vintra Continues to Pioneer Re-Identification Technology
The presence of surveillance cameras has been significantly increased in recent years, as more and more cameras have been installed on public areas such as parking lots, streets, campuses, airports, etc. This has increased the demand for video analytics in order to make sense of all the data coming from the cameras. Video analytics can be performed in various scenarios, such as object tracking, raising an alarm if an object of interest is detected (such as a gun, a person of interest, etc), face recognition, and many more. Most readers will be broadly familiar with face recognition and its capabilities. But what should security leaders do when they do not or cannot use face recognition due to stakeholder concerns, legal issues, or just plain challenging camera angles/conditions but still need the ability to re-identify a person during a critical event? In this post we will focus on an important and emerging field that we are pioneering at Vintra called person re-identification (hereinafter referred to as “Re-id”).
How Does Re-id Technology Work?
Person Re-id is a task of localizing a person in videos that are coming from various cameras that might not share the same field of view (eg. localize a person that was captured by the lobby entrance camera and search for them among the hundreds of cameras at the facility). This means that, given a single reference shot of the person of interest, a user should get back all instances of that person over time in various cameras. This task is very challenging due to variations in pose that can appear through time, difficult lighting conditions, occlusions etc. Similar to face recognition, person re-identification systems retrieve images of one identity, but Re-id does not rely on information of the face but, instead, the whole detection of a person.
The easiest way to tackle the Re-id problem is to do a person search based on some descriptive attributes such as color of clothes, gender, age range, etc. Even though these attributes seem reasonable for humans, they can be very challenging for machines. For example, a red dress captured by one camera can look pink on the other, or there can be various people with the same attributes, for example a construction field where all employees wear the same uniform.
Re-id Technology is Enabled by Convolutional Neural Networks
In recent years, systems being used for person Re-id are based on deep convolutional neural networks (CNN-s), which generate a digital signature of the whole image of a person. A signature is a numerical descriptor that encodes the unique characteristic of the person's image. The similarity of two images of persons can be calculated as a reciprocal value of the distance between two signatures. Ideally, we want the distance of the signatures that belong to the same person to be smaller than the distances between signatures of images of different people.
The CNNs for person Re-id use annotated data that is coming from real case scenarios. Starting from a set of videos recorded by surveillance cameras, we can extract crops of persons from every frame. Crops that belong to the same identity are grouped together and separated from the crops that belong to other identities.
The CNNs for person Re-id are usually trained by optimizing a triplet loss function: L = max(0, dp - dn + m). This loss takes three input signatures, two that belong to the same identity (da and dp) and one that belongs to any other identity (dn). The network is trained to make the distance between the signatures that belong to the same identity smaller than the distance between signatures that belong to different identities. This is the outcome for which it is optimizing. The main problem when training these architectures is that in the beginning of the training process the data is not structured, so sampling an image from a different class that is on a bigger distance than the image from the same class is very probable. However, very quickly, the system learns how to distinguish between easy samples, and the distribution of the training data becomes similar to the scenario from figure 2.
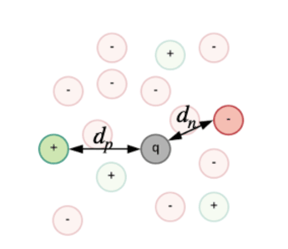
Figure 1. Data distribution in the beginning of training.
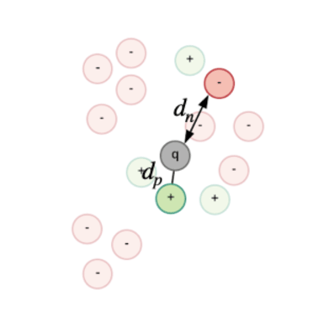
Figure 2. Data distribution later in the training.
Optimizing Machine Learning for Re-id
In order to continue learning from the relevant samples, we have to find a way to sample the negative image that is close to the query. In our recent publications we proposed a novel strategy for mining hard negative samples for siamese network training. We propose storing all data information in a hash table, where images with similar context will be kept in the same hash bin. Each time we sample a query, we choose a negative image from the same hash bin, but from another identity. Every image is assigned to a certain hash bin based on the compact representation of its signature. Every signature is reduced from its original size (usually between 128 and 2048) to its compact representation (of size 10-20). This is done by a linear auto-encoder that learns to reduce the dimension while preserving the important information of the signature. The compact signature h is binarized, and its binary representation is used as a hash entry of the input image (see figure 3).
This way of training neural networks has a few critical advantages: it allows faster training due to better data usage and it provides higher accuracy of the system due to learning from relevant samples for negligible additional computational cost. This system was tested on several publicly available datasets, and it shows significantly better performance than current state-of-the-art approaches. For more information on the technology and these test results, check our publications on this important topic below.
References
Fast hard negative mining for deep metric learning, Bojana Gajić, PhD, Ariel Amato, PhD, and Carlo Gatta, PhD, Pattern Recognition, Volume 112, 2021, 107795, ISSN 0031-3203, https://www.sciencedirect.com/science/article/abs/pii/S0031320320305987
Bag of Negatives for Siamese Architectures, Bojana Gajić, PhD, Ariel Amato, PhD, and Carlo Gatta, PhD, British Machine Vision Conference, 2019, https://bmvc2019.org/wp-content/uploads/papers/0934-paper.pdf
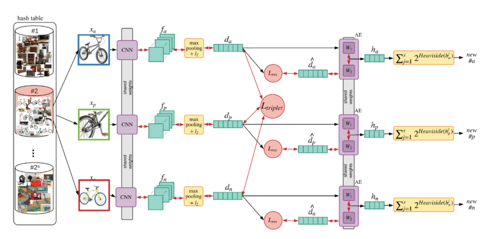
Figure 3. Re-id training system.
Re-Identification On-Demand Demo
If you’d like to see a demo of the Re-id solution in action, you can watch a short clip of the technology working on a person and vehicle by clicking below.

Comments are closed.